Designing Succinct, a smallest-pass finder for LLM systems.
Succinct turns an expensive question, "which model should we ship?", into a measured product loop: define the task, generate or verify truth, run a model ladder, stop when confidence is high enough, and deploy the cheapest passing route.
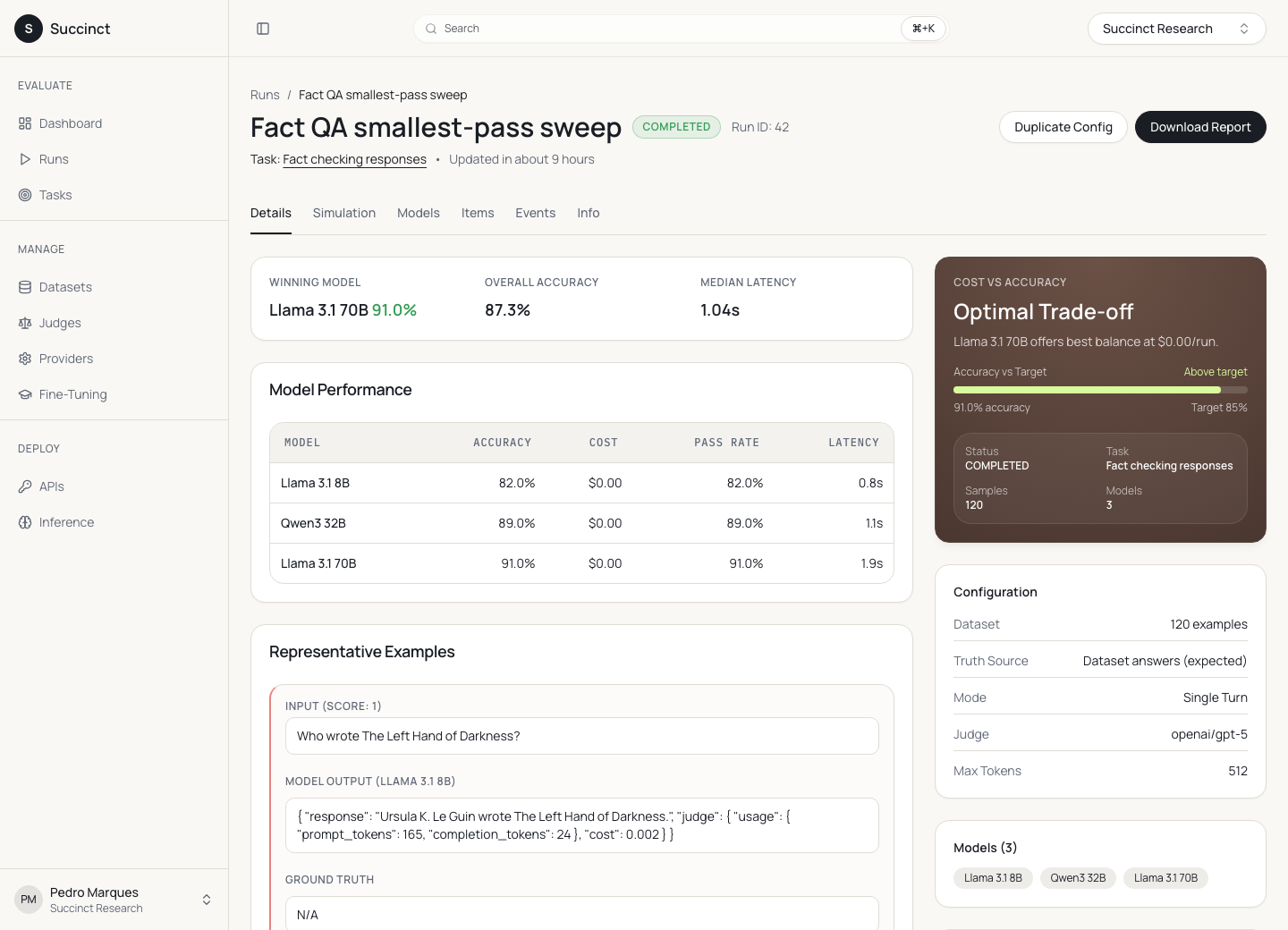
The run-detail surface is the core product artifact: one place to inspect the winner, the confidence target, the cost trade-off, the dataset configuration, and the examples that explain why a model passed or failed.
Most LLM product work starts with vibes. Teams try the biggest model, try a cheaper one, read a few examples, then make a choice that can quietly turn into a large recurring cost. Succinct was designed around the opposite posture: a smaller model is not a downgrade if it passes the task with enough evidence.
The product I built is part evaluation workbench, part architecture tool, and part deployment console. It has to feel approachable enough for a designer or product lead to start a run, but precise enough for an engineer to trust the numbers behind a production routing decision.
The product shape
The main loop is intentionally narrow. A task holds the dataset and rubric. A judge defines the pass/fail contract. A run evaluates a ladder of candidate models against a target success rate and confidence level. The output is not a beauty contest leaderboard; it is a deployment recommendation.
Decision loop
Every run reduces model choice to four measured gates.
85%Target success rate
95%Confidence level
120Examples sampled
01 TaskFreeze the workload
Dataset rows, expected answers, rubric, sample size, and target quality are captured before the run starts.
/
02 JudgeTurn quality into pass/fail
Programmatic rules and an LLM judge produce auditable reasons, not just aggregate scores.
/
03 LadderStart small and climb
Candidate models are evaluated in cost order, with tokens, latency, pass rate, and Wilson lower bound recorded.
The UI mirrors the architecture. Users configure a task, judge, model ladder, and statistical target, then the backend runs the loop and streams progress back into the interface.
Getting actual decisions onto the screen
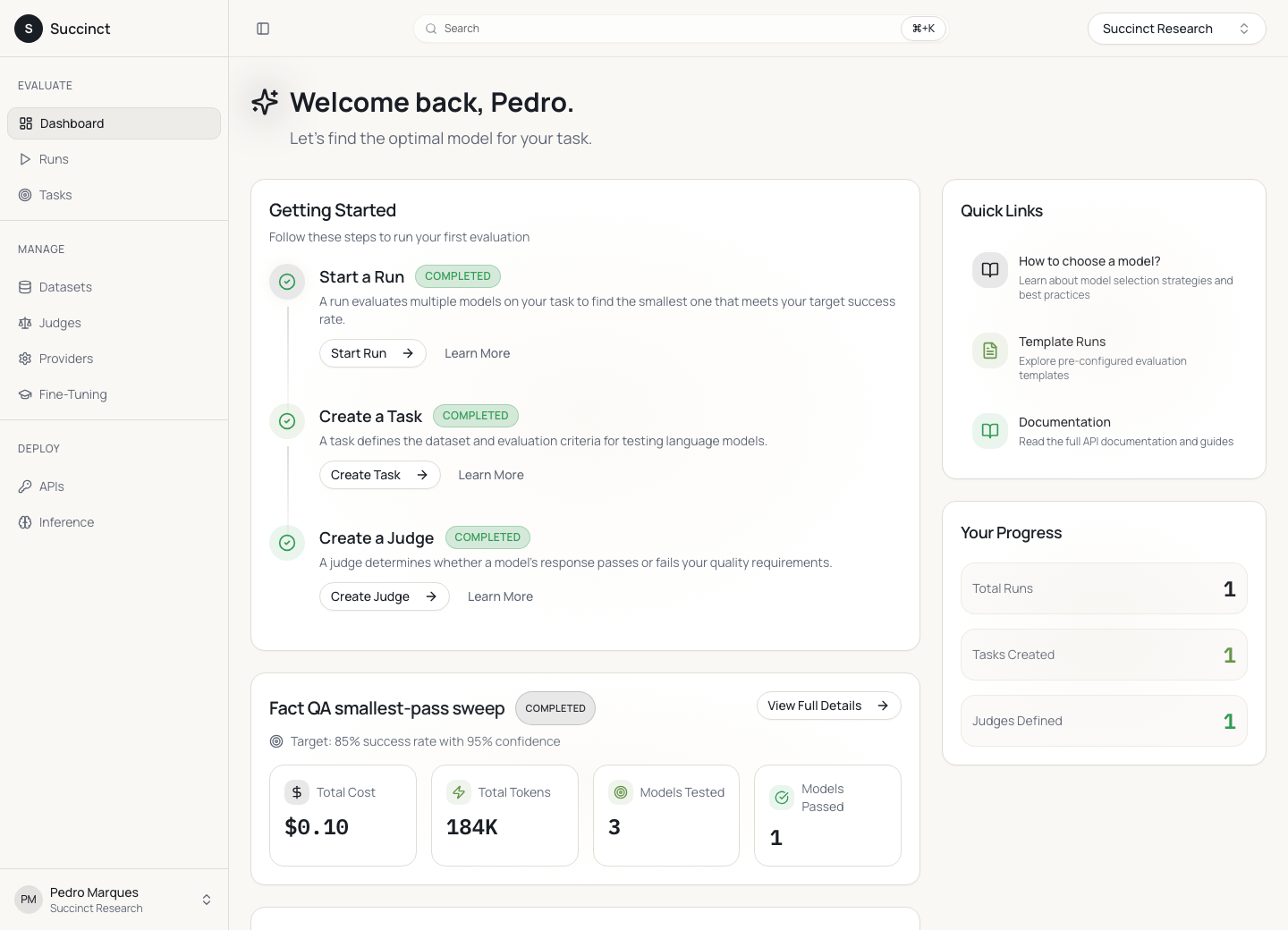
The dashboard is deliberately operational. It opens with the steps that make a valid evaluation possible, then shows the last run as a reusable artifact: cost, token count, models tested, and how many models cleared the threshold. This avoids a common analytics trap where the user is shown many charts before they know whether the system found anything useful.
The dashboard makes the evaluation workflow visible: create a task, create a judge, start a run, then keep the latest run one click away.
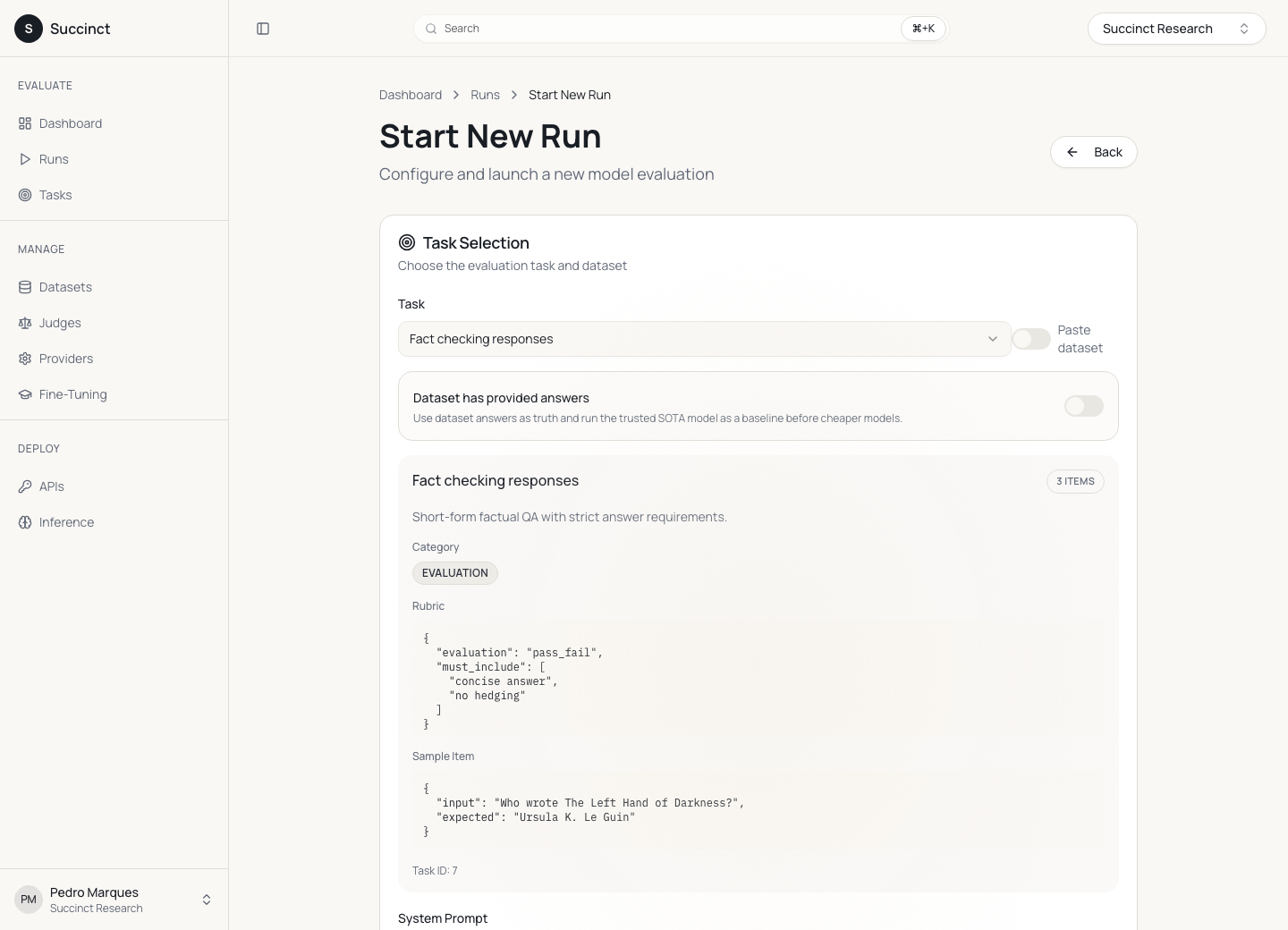
The start-run screen is the point where the product earns trust. It has to expose enough detail to be reproducible without forcing a user to think like the backend. That is why the selected task preview shows the category, rubric, sample item, answer-field mode, system prompt, batch size, and the model ladder in one long configuration flow.
Left: run setup with task/rubric context. Right: deployment surface for turning the winning model into an API-key restricted production route.
The statistical decision
A raw pass rate is too optimistic for product routing. If a model passes 102 out of 120 examples, the observed rate is 85%, but the lower confidence bound can still sit below the target. Succinct uses the Wilson lower bound so a model only passes when the pessimistic estimate clears the user-defined threshold.
That changes the product behavior. The app is not asking "which model had the highest score in this run?" It is asking "which is the smallest model whose lower-bound quality is good enough to ship?"
Smallest-pass finder
The first lower bound above target wins.
$0.037Winning run cost
84.2%Lower bound
1.12sAverage latency
Candidate 01
Llama 3.1 8B
Observed pass rate is 82.0%, but the Wilson lower bound is 75.5%. Too uncertain for an 85% target.
Candidate 02
Qwen3 32B
Observed pass rate is 89.0%. Lower bound is close enough for the configured run and cheaper than larger alternatives.
Candidate 03
Llama 3.1 70B
Higher quality, but more cost and latency. Kept as evidence, not selected as the default route.
Decision
Stop climbing
The interface frames the result as a routing decision: use the smallest passing model, not the biggest model that looks safest.
The decision visualization translates statistical confidence into a product rule. The selected model is the first candidate that clears the quality bar under the configured target, not simply the biggest or most accurate model.
Architecture
The system is split into a React evaluation console and a FastAPI service. The frontend uses Vite, React Router, TanStack Query, shadcn/Radix primitives, and Server-Sent Events. The backend uses FastAPI, async SQLAlchemy, Alembic migrations, PostgreSQL, OpenRouter-compatible model calls, and an async evaluation worker.
System map
A run is durable data plus a live event stream.
React console
Dashboard, datasets, judges, run setup, run detail, API keys, providers, inference, and fine-tuning surfaces. TanStack Query owns fetch/cache behavior.
ReactViteRadixRecharts
FastAPI service
Typed REST endpoints for tasks, judges, runs, models, API keys, providers, inference, organizations, and auth. SSE streams run events.
FastAPIPydanticSSE
Evaluation worker
Generates trusted references when needed, loops through the model ladder, scores each item, updates aggregate stats, records costs, and emits progress events.
asyncioOpenRouterWilson CI
PostgreSQL records
Tasks, judge definitions, runs, model evaluations, item evaluations, run events, users, organizations, provider config, API keys, and usage logs.
SQLAlchemyAlembicasyncpg
Deployment layer
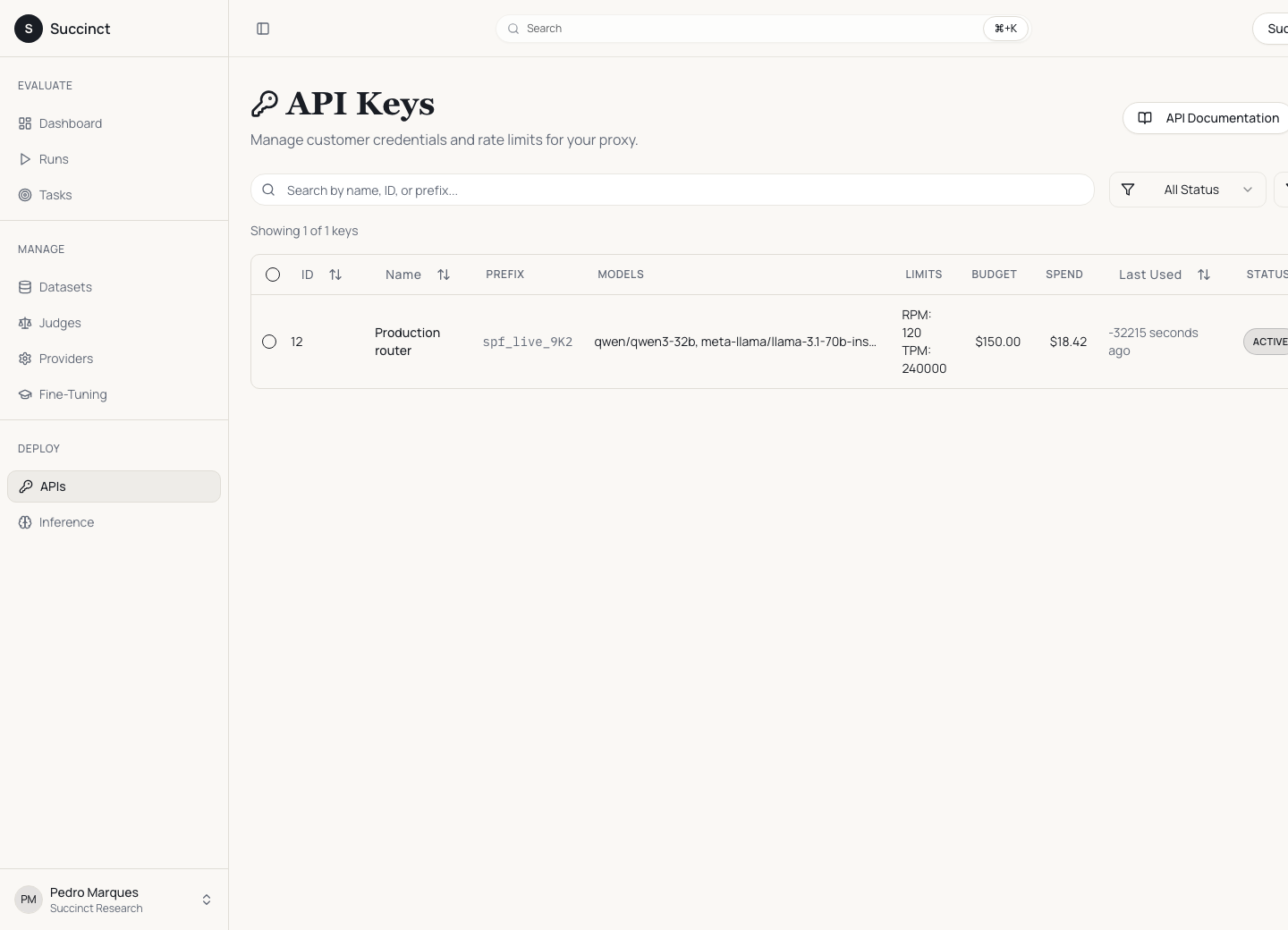
After a run, the API-key surface makes the recommendation operational: restrict credentials to approved models, set RPM/TPM limits, track spend, and expose an OpenAI-compatible proxy for application code.
The important architecture decision is preserving run evidence as first-class data. A passing route is not just a chosen model string; it is a task, judge, dataset, configuration, item evidence, aggregate metrics, and event log.
Design details that make it useful
Succinct is dense because the domain is dense. The design work was not to hide complexity; it was to stage it. The first screen answers "what do I do next?" The run setup answers "what exactly will be evaluated?" The results screen answers "what can I ship and why?"
Configuration stays visible. Dataset size, truth source, judge, max tokens, and model list remain adjacent to the result, so a screenshot of a run is still interpretable.
Examples explain the aggregate. Representative inputs, model outputs, ground truth, and judge reasons sit below the table so failures can be audited instead of treated as black-box noise.
Cost is a product metric, not a footnote. The interface shows total cost, cost per success, token usage, latency, and API spend because model choice is a business decision.
The deployment step is part of the workflow. API keys, provider config, usage logs, and rate limits turn evaluation output into a route that can be controlled in production.
The portfolio thesis: Succinct is not another generic LLM dashboard. It is an argument that AI product teams should choose models by measured sufficiency, not brand gravity. The design turns that argument into a workflow engineers can run repeatedly.
What I would harden next
The prototype already has the core product loop: auth, organizations, tasks, judges, run orchestration, model catalog, SSE progress, result analysis, API keys, providers, inference, and fine-tuning screens. The next engineering step is operational durability: move evaluation work out of in-process asyncio.create_task into a supervised queue, add stricter cancellation semantics, and make pricing data provider-backed instead of estimated.
The design direction would also keep tightening the connection between evidence and deployment. A strong next version would let a team promote a winning run into a named production policy, attach rollback thresholds, and monitor drift against the original evaluation dataset.
Built as a product and architecture portfolio case study by Pedro Marques.